- Published on
AWS E-Commerce Platform Architecture for Million-Scale Users 🛒
- Authors

- Name
- Chengchang Yu
- @chengchangyu
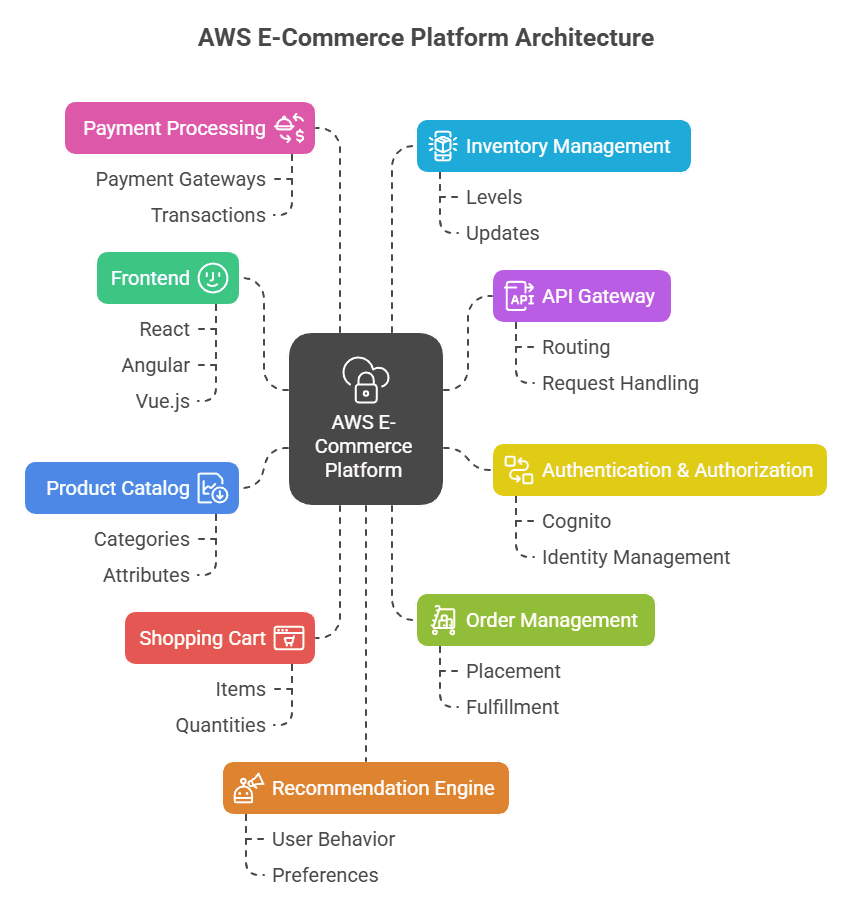
AWS E-Commerce Platform Architecture
If you were to design an AWS E-Commerce Platform capable of handling millions of users, what key architectural decisions would you make? I explored this challenge with Gemini × Claude, and together we mapped out a scalable, event-driven solution.
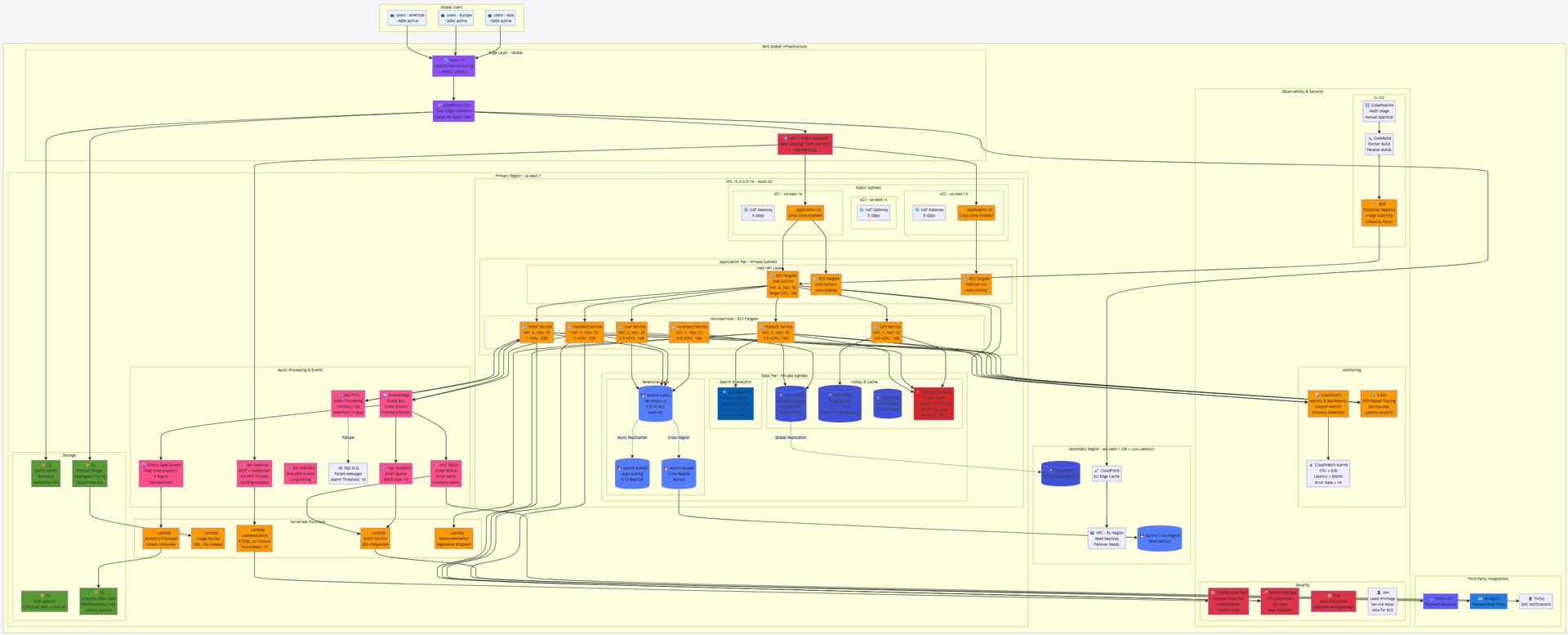
AWS E-Commerce Platform - Million Scale Architecture (generated via Claude Sonnet 4.5)
Architecture Highlights 🎯
High Availability Design
Multi-AZ Deployment
3 Availability Zones (us-east-1a, 1b, 1c)
├─ Application: ECS Fargate across all AZs
├─ Database: Aurora Multi-AZ with auto-failover
├─ Cache: ElastiCache Redis with replicas
└─ NAT Gateways: One per AZ (no single point of failure)
Cross-Region DR
Primary: us-east-1 (Active)
Secondary: eu-west-1 (Standby + Read Traffic)
├─ Aurora Cross-Region Replica (< 1s lag)
├─ DynamoDB Global Tables (active-active)
└─ Automated Failover: RTO < 5 min, RPO < 1 min
Auto-Scaling Strategy
ECS Fargate:
├─ Target Tracking: CPU 70%, Memory 80%
├─ Step Scaling: +10 tasks when CPU > 85%
└─ Scheduled Scaling: +20% capacity during peak hours
Aurora Serverless v2:
├─ Min: 0.5 ACU (idle)
├─ Max: 16 ACU (peak load)
└─ Scale in 0.5 ACU increments
Read Replicas:
└─ Auto-scaling: 0-15 replicas based on CPU/connections
Low Latency Optimization
Global Edge Network
CloudFront CDN:
├─ 300+ Edge Locations worldwide
├─ Cache Hit Ratio Target: 80%+
├─ TTL Strategy:
│ ├─ Static Assets: 1 year
│ ├─ Product Images: 7 days
│ ├─ API Responses: 5 minutes (for product listings)
│ └─ Dynamic Content: No cache
└─ Regional Edge Caches for better cache efficiency
Caching Strategy (Multi-Layer)
Layer 1: CloudFront (Edge) - 50-100ms global latency
Layer 2: ElastiCache Redis (Regional) - 1-5ms latency
Layer 3: DynamoDB DAX (Optional) - sub-millisecond
Layer 4: Application Memory Cache - microseconds
Database Read Optimization
Read-Heavy Workloads:
├─ Product Catalog: DynamoDB (single-digit ms)
├─ User Sessions: DynamoDB (TTL auto-cleanup)
├─ Shopping Cart: DynamoDB + Redis cache
└─ Order History: Aurora Read Replicas (read scaling)
Write-Heavy Workloads:
├─ Order Processing: Aurora Primary + SQS buffering
├─ Inventory Updates: DynamoDB (1000s writes/sec)
└─ Analytics Events: Kinesis (real-time streaming)
Latency Targets
P50 Latency: < 100ms (API responses)
P95 Latency: < 300ms
P99 Latency: < 500ms
Time to First Byte (TTFB): < 200ms globally
Cost Optimization
Monthly Cost Estimate: 22,000 (Budgetary Estimate)
Compute (40% = $5,600 - $8,800):
├─ ECS Fargate: ~50 tasks average (Note: This will scale significantly higher during peak periods to handle the load, impacting the average cost)
│ └─ 0.5-1 vCPU, 1-2GB RAM per task
├─ Lambda: 10M invocations/month (mostly free tier)
└─ Savings: Use Fargate Spot for non-critical workloads (-70%)
Database (35% = $4,900 - $7,700):
├─ Aurora Serverless v2: 4-8 ACU average (Note: Sustained peak usage will drive costs towards the higher end of this estimate)
├─ DynamoDB: On-Demand pricing (pay per request) (Note: A significant cost component due to the high volume of read/write operations)
├─ ElastiCache: 3x cache.r6g.large (reserved instances -40%)
└─ OpenSearch: 3x r6g.large.search (reserved instances)
Storage (7% = $1,000 - $1,500):
├─ S3: 5TB storage + 10TB transfer
├─ CloudFront: 20TB data transfer
└─ Lifecycle policies: Auto-tier to Glacier after 90 days
Networking (10% = $1,500-2,500):
├─ NAT Gateways: 3x $45/month
├─ ALB: 2x $23/month + LCU charges
└─ Data Transfer: Inter-AZ + Internet egress (Note: A major driver of networking costs due to Multi-AZ architecture and high traffic volumes)
Other (8% = $1,000-1,500):
├─ Route 53, WAF, CloudWatch, X-Ray
├─ Secrets Manager, KMS
└─ Third-party: Stripe (2.9% + $0.30), SendGrid, Twilio
Cost Optimization Strategies
1. Compute Savings
✅ Use Fargate Spot for batch jobs (70% savings)
✅ Right-size containers: Start small, scale based on metrics
✅ Lambda provisioned concurrency only for critical functions
✅ Schedule scale-down during off-peak hours (2am-6am)
2. Database Savings
✅ Aurora Serverless v2: Pay only for active capacity
✅ DynamoDB On-Demand: No idle capacity costs
✅ Reserved Instances for ElastiCache (1-year, 40% off)
✅ Read replicas only during peak hours
3. Storage Savings
✅ S3 Intelligent-Tiering: Auto-optimize storage class
✅ CloudFront: Optimize cache hit ratio to reduce origin requests
✅ Image compression: WebP format (30% smaller)
✅ Lifecycle policies: Delete old logs after 90 days
4. Networking Savings
✅ Use VPC Endpoints for S3/DynamoDB (no NAT Gateway charges)
✅ CloudFront: Reduce origin requests with longer TTLs
✅ Compress responses: gzip/brotli (reduce transfer costs)
Performance Benchmarks 📊
Capacity Planning
Concurrent Users: 1,000,000 total
├─ Peak Concurrent: 50,000 users
├─ Average Session: 15 minutes
└─ Requests per User: 20 requests/session
Total Traffic:
├─ Peak QPS: 10,000 requests/second
├─ Average QPS: 2,000 requests/second
├─ Daily Requests: ~170 million
└─ Monthly Requests: ~5 billion
Database Load:
├─ Aurora: 5,000 reads/sec, 500 writes/sec
├─ DynamoDB: 10,000 reads/sec, 2,000 writes/sec
└─ Cache Hit Rate: 95% (reduces DB load by 20x)
Scalability Limits
Current Architecture Supports:
├─ 100,000 concurrent users (2x headroom)
├─ 20,000 QPS (2x headroom)
├─ 10,000 orders/hour
└─ 1 million products in catalog
Scale-Up Path:
├─ Add more ECS tasks (up to 500+)
├─ Add Aurora read replicas (up to 15)
├─ Increase ElastiCache shards (up to 500 nodes)
└─ DynamoDB auto-scales to millions of requests/sec
Security Best Practices 🔒
Network Security:
├─ WAF: Block SQL injection, XSS, bad bots
├─ Security Groups: Least privilege (only required ports)
├─ NACLs: Subnet-level firewall rules
└─ Private Subnets: No direct internet access for app/data tiers
Data Security:
├─ Encryption at Rest: KMS for all data stores
├─ Encryption in Transit: TLS 1.3 everywhere
├─ Secrets Management: No hardcoded credentials
└─ Database Encryption: Aurora + DynamoDB native encryption
Identity & Access:
├─ Cognito: User authentication with MFA
├─ IAM Roles: Service-to-service authentication
├─ Least Privilege: Each service has minimal permissions
└─ Audit Logging: CloudTrail for all API calls
Application Security:
├─ Input Validation: Server-side validation
├─ Rate Limiting: API Gateway throttling
├─ CORS: Strict origin policies
└─ Dependency Scanning: ECR image scanning
Monitoring & Alerting 📊
Key Metrics Dashboard
Golden Signals:
├─ Latency: P50, P95, P99 response times
├─ Traffic: Requests per second by service
├─ Errors: 4xx/5xx error rates
└─ Saturation: CPU, memory, database connections
Business Metrics:
├─ Orders per minute
├─ Cart abandonment rate
├─ Payment success rate
├─ Search conversion rate
└─ Revenue per hour
Critical Alarms
🚨 P1 Alarms (Immediate Response):
├─ API Gateway 5xx > 1% for 5 minutes
├─ Payment Service error rate > 0.5%
├─ Database CPU > 90% for 10 minutes
├─ Order processing queue depth > 10,000
└─ CloudFront 5xx > 5% for 5 minutes
⚠️ P2 Alarms (15-min Response):
├─ ECS task failure rate > 5%
├─ Cache hit rate < 80%
├─ API latency P95 > 500ms
└─ Lambda concurrent executions > 800
📊 P3 Alarms (Review Next Day):
├─ Daily cost > $500
├─ S3 storage growth > 20% week-over-week
├─ Unusual traffic patterns (anomaly detection)
└─ Security Group changes (CloudTrail)
Deployment Strategy 🚀
CI/CD Pipeline
Code Commit → GitHub
↓
CodePipeline Triggered
↓
CodeBuild (Parallel):
├─ Run Unit Tests
├─ Run Integration Tests
├─ Build Docker Image
├─ Scan for Vulnerabilities
└─ Push to ECR
↓
Deploy to Dev Environment
↓
Automated E2E Tests
↓
Manual Approval (for Prod)
↓
Blue/Green Deployment to Prod
├─ Deploy to "Green" environment
├─ Run smoke tests
├─ Shift 10% traffic → Monitor
├─ Shift 50% traffic → Monitor
└─ Shift 100% traffic → Complete
↓
Rollback if error rate > 1%
Zero-Downtime Deployment
ECS Blue/Green:
├─ New task definition deployed
├─ Health checks pass
├─ ALB shifts traffic gradually
└─ Old tasks drained and terminated
Database Migrations:
├─ Backward-compatible changes only
├─ Schema changes in separate deployment
├─ Use Aurora zero-downtime patching
└─ Test on read replica first
Disaster Recovery Plan 🆘
RTO & RPO Targets
Tier 1 Services (Critical):
├─ Order Processing, Payment
├─ RTO: < 5 minutes
├─ RPO: < 1 minute
└─ Strategy: Active-Active cross-region
Tier 2 Services (Important):
├─ Product Catalog, User Service
├─ RTO: < 15 minutes
├─ RPO: < 5 minutes
└─ Strategy: Warm standby in secondary region
Tier 3 Services (Non-Critical):
├─ Analytics, Recommendations
├─ RTO: < 1 hour
├─ RPO: < 1 hour
└─ Strategy: Backup and restore
Failover Procedures
Automated Failover:
├─ Route 53 health checks detect failure
├─ Traffic automatically routed to eu-west-1
├─ Aurora promotes read replica to primary
├─ DynamoDB Global Tables (already active)
└─ CloudWatch alarm triggers runbook
Manual Failover (if needed):
1. Promote Aurora replica in DR region
2. Update Route 53 to point to DR region
3. Scale up ECS tasks in DR region
4. Verify all services healthy
5. Communicate to stakeholders
Migration Roadmap 🗺️
Phase 1: Foundation (Week 1-2)
✅ Set up VPC, subnets, security groups
✅ Deploy Aurora, DynamoDB, ElastiCache
✅ Configure CloudFront, Route 53, WAF
✅ Set up IAM roles, Secrets Manager
Phase 2: Core Services (Week 3-4)
✅ Deploy Product Service (read-only first)
✅ Deploy User Service + Cognito
✅ Deploy Cart Service
✅ Migrate product catalog to DynamoDB
✅ Set up monitoring and alarms
Phase 3: Transactions (Week 5-6)
✅ Deploy Order Service
✅ Deploy Payment Service (Stripe integration)
✅ Deploy Inventory Service
✅ Set up event-driven architecture (SQS, SNS, EventBridge)
✅ Load testing (simulate 10K QPS)
Phase 4: Optimization (Week 7-8)
✅ Fine-tune caching strategy
✅ Optimize database queries
✅ Set up cross-region replication
✅ Implement auto-scaling policies
✅ Chaos engineering tests
Phase 5: Go-Live (Week 9)
✅ Final load testing (50K concurrent users)
✅ DR failover drill
✅ Cutover plan execution
✅ Monitor for 48 hours
✅ Post-launch optimization