- Published on
The Anatomy of a Cloud Catastrophe - Dissecting the AWS us-east-1 Outage ☁
- Authors

- Name
- Chengchang Yu
- @chengchangyu
Executive Summary
On a day that will be remembered in cloud computing history, AWS's us-east-1 region—the oldest and largest AWS data center located in Virginia—experienced a catastrophic outage that affected 113 services and countless businesses worldwide. What started as a routine technical update to DynamoDB's API cascaded into one of the most significant cloud infrastructure failures in recent years.
This post provides a deep architectural analysis of what went wrong, why it happened, and the critical lessons for cloud architects and engineering leaders. (Note: this is from my own understanding and not an official AWS explanation.)
The Timeline: From Update to Disaster
Initial Trigger: A technical update was deployed to DynamoDB's API through AWS Systems Manager.
First Failure: The update contained an error that corrupted the Domain Name System (DNS) records.
Cascade Begins: Within minutes, DynamoDB became unreachable across all three Availability Zones (1a, 1b, 1c).
Amplification: IAM (Identity and Access Management) failed because it depends on DynamoDB for state management.
Total Collapse: With IAM down, virtually every AWS service lost the ability to authenticate requests.
Recovery: By 10:11 GMT, AWS declared all services operational, though message backlogs took hours to clear.
The Architecture: Understanding the Cascade
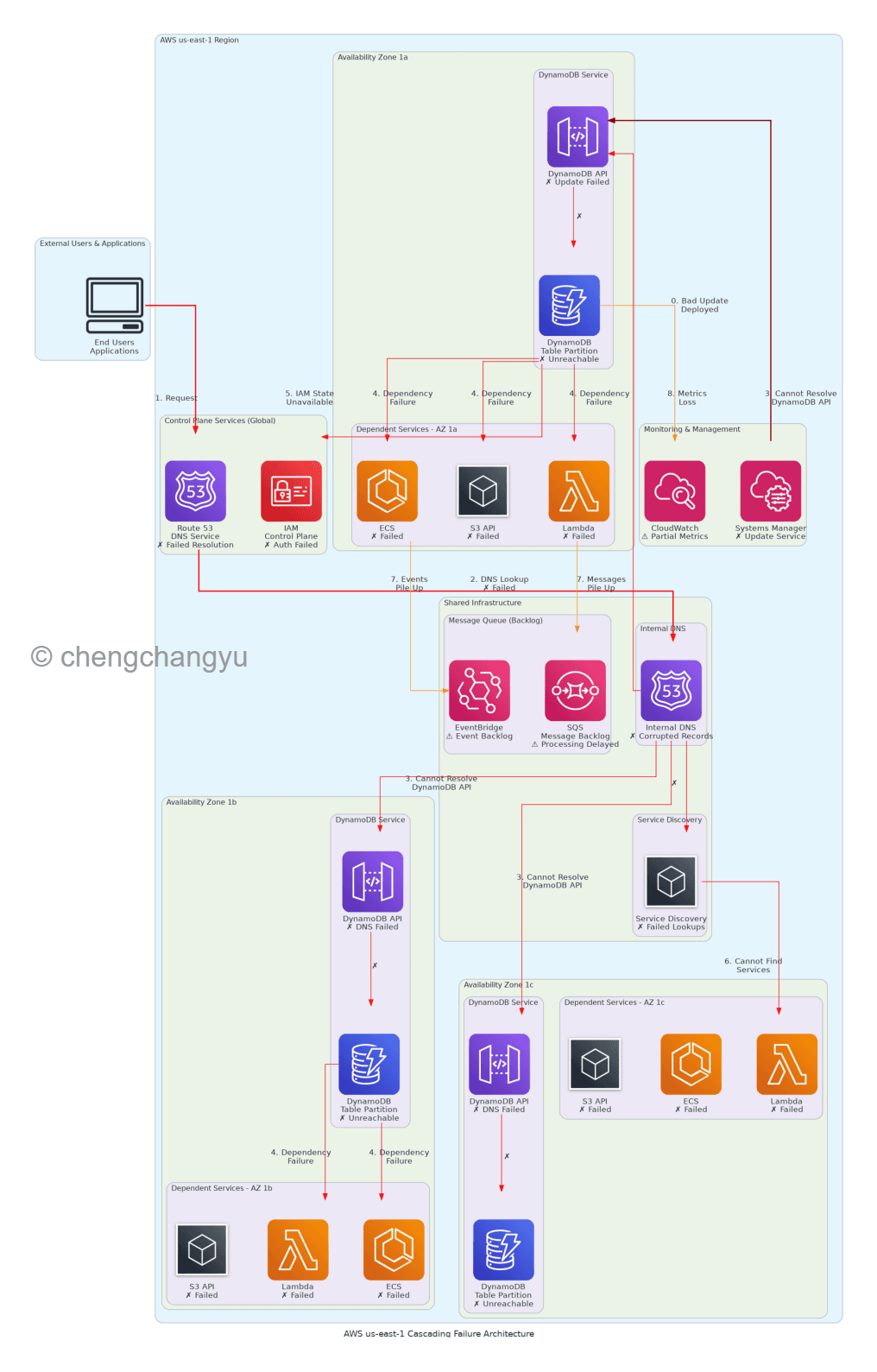
AWS Outage Architecture
Layer 1: The DNS Foundation
DNS serves as the internet's phone book, translating human-readable service names into IP addresses that computers use to connect. In AWS's internal architecture:
- Route 53 handles external DNS resolution for customer traffic
- Internal DNS services manage service-to-service communication within AWS
- Service Discovery relies on DNS to locate API endpoints
When the DynamoDB update corrupted DNS records, applications could no longer find the IP addresses for DynamoDB's API endpoints. This seemingly simple failure became the foundation of the catastrophe.
Layer 2: DynamoDB as a Critical Dependency
DynamoDB isn't just another database service—it's a foundational component that many AWS services depend on:
- State Management: Services store operational state in DynamoDB
- Configuration Data: Service configurations and metadata
- Session Information: User session data and authentication tokens
- Service Coordination: Cross-service communication metadata
When DynamoDB went down across all three Availability Zones simultaneously, it created a domino effect that no redundancy architecture could prevent.
Layer 3: The IAM Amplification Effect
Here's where the outage transformed from serious to catastrophic. AWS's IAM service—responsible for authenticating and authorizing every API call—depends on DynamoDB for:
- User credential verification
- Role assumption operations
- Policy evaluation
- Token generation and validation
The Critical Failure: When IAM lost access to DynamoDB, it could no longer authenticate requests. This meant:
- Lambda functions couldn't execute
- ECS containers couldn't start
- S3 API calls failed
- EC2 instances couldn't be launched or managed
- Virtually every AWS service became inaccessible
Layer 4: Service Discovery Breakdown
AWS's internal service mesh relies on sophisticated service discovery mechanisms:
- Services register their endpoints in a distributed registry
- Other services query this registry to find dependencies
- Health checks continuously validate service availability
With DNS corrupted and DynamoDB unavailable, the entire service discovery infrastructure collapsed. Services couldn't locate each other, creating a network of isolated, non-functional components.
Layer 5: The Message Queue Backlog
As services failed, message queues like SQS and EventBridge accumulated massive backlogs:
- Failed requests triggered automatic retries
- Event-driven architectures generated cascading events
- Dead letter queues filled up
- Processing delays compounded across the system
Even after core services recovered, clearing these backlogs took hours, extending the impact of the outage.
Layer 6: Monitoring Blindness
Adding insult to injury, CloudWatch—AWS's monitoring service—experienced partial degradation:
- Metrics collection became unreliable
- Logs were delayed or lost
- Alarms failed to trigger properly
- Dashboard data became stale
This monitoring blindness made troubleshooting significantly more difficult, as engineers couldn't see the full scope of the problem in real-time.
The Critical Design Flaws Exposed
1. Single Region, Multiple Failure Domains
Despite having three Availability Zones, the outage affected all zones simultaneously because:
- DNS and DynamoDB control planes are region-scoped, not AZ-scoped
- A region-level failure can bypass AZ isolation
- Shared infrastructure components created hidden dependencies
Lesson: Multi-AZ architecture protects against infrastructure failures, not control plane failures.
2. Circular Dependencies in Critical Services
The IAM-DynamoDB dependency created a circular failure mode:
- DynamoDB needs IAM for access control
- IAM needs DynamoDB for state management
- When one fails, both fail
- Recovery becomes nearly impossible without manual intervention
Lesson: Critical authentication services should have independent, isolated data stores.
3. DNS as a Hidden Single Point of Failure
While everyone focuses on database and compute redundancy, DNS often gets overlooked:
- DNS failures are invisible until they cause cascading problems
- DNS caching can mask problems temporarily, then fail catastrophically
- Internal DNS has different failure modes than external DNS
Lesson: DNS infrastructure requires the same level of redundancy and testing as any critical service.
4. Insufficient Blast Radius Containment
The update that triggered the outage affected the entire region:
- No gradual rollout or canary deployment
- No circuit breakers to isolate the failure
- No automatic rollback mechanisms
Lesson: Even internal updates need progressive deployment strategies.
What This Means for Cloud Architects
Immediate Actions
Audit Your Dependencies: Map out which AWS services your application depends on, including indirect dependencies through IAM, DNS, and service discovery.
Implement Multi-Region Strategies: For critical workloads, active-active or active-passive multi-region architectures are no longer optional.
Design for Degraded Operation: Your applications should have fallback modes that work even when authentication or service discovery fails.
Test Failure Scenarios: Regularly conduct chaos engineering exercises that simulate control plane failures, not just data plane failures.
Strategic Considerations
Rethink "High Availability": Traditional HA architectures assume infrastructure failures, not control plane failures. Your definition of HA needs to evolve.
Embrace Multi-Cloud: Not for cost optimization, but for true resilience. Critical services should be able to fail over to different cloud providers.
Build Observability Independence: Your monitoring and alerting should not depend on the same infrastructure you're monitoring.
Question Vendor Architectures: Don't assume cloud providers have solved these problems. Ask hard questions about their internal dependencies.
The Broader Implications
This outage reveals uncomfortable truths about cloud computing:
Centralization Risk
The cloud industry's consolidation around a few major providers (AWS, Azure, GCP) creates systemic risk. When AWS us-east-1 goes down, a significant portion of the internet goes with it.
Complexity Debt
Modern cloud architectures have become so complex that even the providers themselves struggle to understand all the dependencies. This complexity is technical debt that will eventually come due.
The Illusion of Redundancy
Multi-AZ, auto-scaling, and load balancing create an illusion of invulnerability. This outage proved that logical failures can bypass all physical redundancy.
Control Plane vs. Data Plane
The industry has focused heavily on data plane resilience (handling traffic, processing requests) while underinvesting in control plane resilience (authentication, service discovery, configuration management).
Lessons for Engineering Leaders
1. Invest in Resilience Engineering
Resilience isn't about preventing failures—it's about limiting their impact and recovering quickly. This requires:
- Dedicated teams focused on failure scenarios
- Regular game days and chaos experiments
- Post-incident reviews that drive architectural changes
2. Challenge Your Assumptions
Every "impossible" failure scenario should be tested:
- What if IAM goes down?
- What if DNS stops working?
- What if our monitoring system fails?
- What if multiple regions fail simultaneously?
3. Build for Graceful Degradation
Applications should have multiple operational modes:
- Full functionality: Everything works normally
- Degraded mode: Core features work, nice-to-haves are disabled
- Survival mode: Minimal functionality to prevent data loss
4. Document and Communicate Dependencies
Create architectural diagrams that show:
- Direct service dependencies
- Indirect dependencies through shared infrastructure
- Failure propagation paths
- Recovery time objectives for each component
The Path Forward
This outage is a wake-up call for the entire cloud industry. Here's what needs to change:
For Cloud Providers
- Isolate Critical Services: Authentication and DNS should be completely isolated from other services
- Implement Progressive Rollouts: Every change, even internal ones, needs gradual deployment
- Build Better Circuit Breakers: Failures should be contained, not amplified
- Improve Transparency: Customers need better visibility into service dependencies
For Cloud Users
- Demand Better SLAs: Current SLAs don't account for control plane failures
- Build True Multi-Region: Accept the cost and complexity of real geographic redundancy
- Maintain Hybrid Capabilities: Keep some on-premises capability for critical functions
- Invest in Expertise: Understanding cloud architecture is now a core business competency
Conclusion: The New Normal
Cloud outages like this are not anomalies—they're the inevitable result of building increasingly complex distributed systems. The question isn't whether they'll happen again, but when and how severe they'll be.
As cloud architects and engineering leaders, our responsibility is to:
- Understand the true architecture of our cloud dependencies
- Design for failure at every level, including control planes
- Test our assumptions through rigorous failure injection
- Communicate risks honestly to business stakeholders
The AWS us-east-1 outage taught us that redundancy without understanding is just expensive complexity. True resilience requires deep architectural knowledge, rigorous testing, and the humility to accept that any system can fail.
The clouds will fail again. The question is: will your systems survive when they do?